
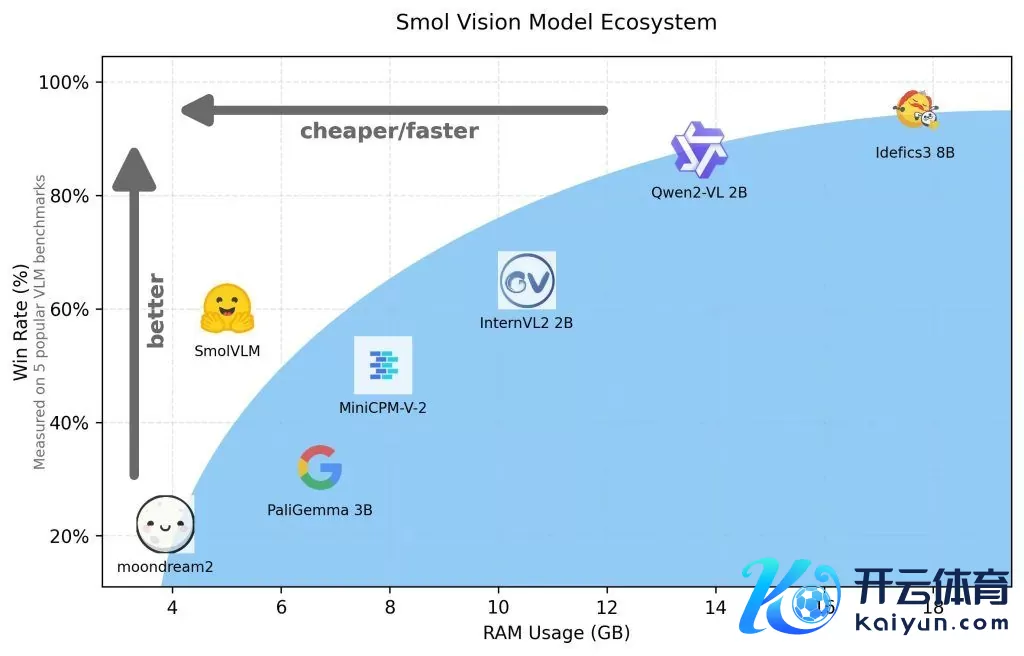
IT之家 11 月 27 日音问,Hugging Face 平台昨日(11 月 26 日)发布博文,通知推出 SmolVLM AI 视觉言语模子(VLM),仅有 20 亿参数,用于教悔端推理,凭借其极低的内存占用在同类模子中脱颖而出。
官方暗意 SmolVLM AI 模子的优点在于体积小、速率快、内存高效,何况饱和开源,悉数模子查验点、VLM 数据集、锻练配方和器用均在 Apache 2.0 许可证下发布。
SmolVLM AI 模子共有 SmolVLM-Base(用于卑鄙微调)、SmolVLM-Synthetic(基于合成数据微调)和 SmolVLM-Instruct(辅导微调版块,不错径直用于交互式诈骗)三个版块。
架构
SmolVLM 最大的特色在于狡饰的架构运筹帷幄,模仿了 Idefics3,使用了 SmolLM2 1.7B 动作言语骨干,通过像素混洗政策将视觉信息的压缩率进步到 9 倍。
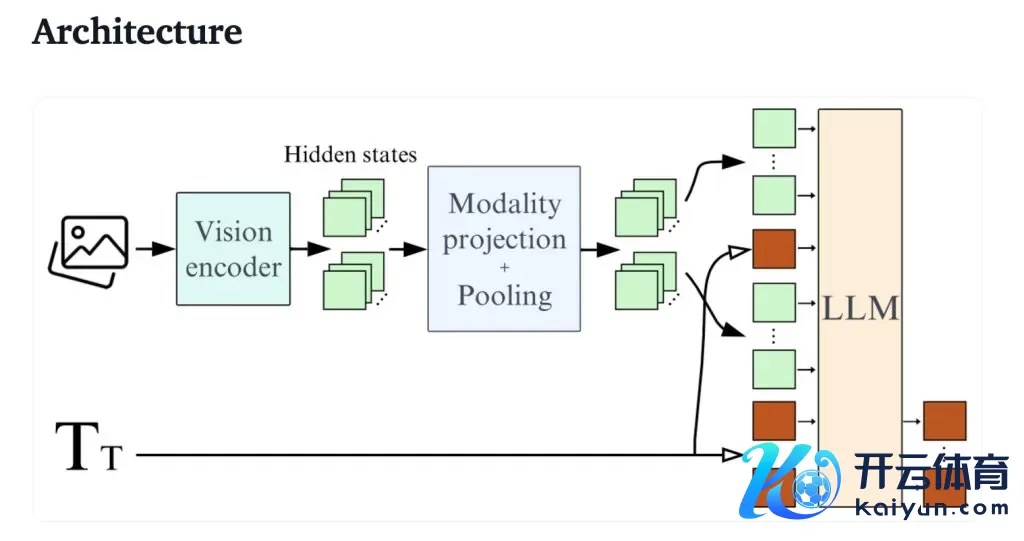
锻练数据集包括 Cauldron 和 Docmatix,并对 SmolLM2 进行了高下文膨大,使其大概处理更长的文本序列和多张图像。该模子通过优化图像编码和推理经过,灵验裁汰了内存占用,处置了以往大型模子在平方教悔上开动迟缓甚而崩溃的问题。
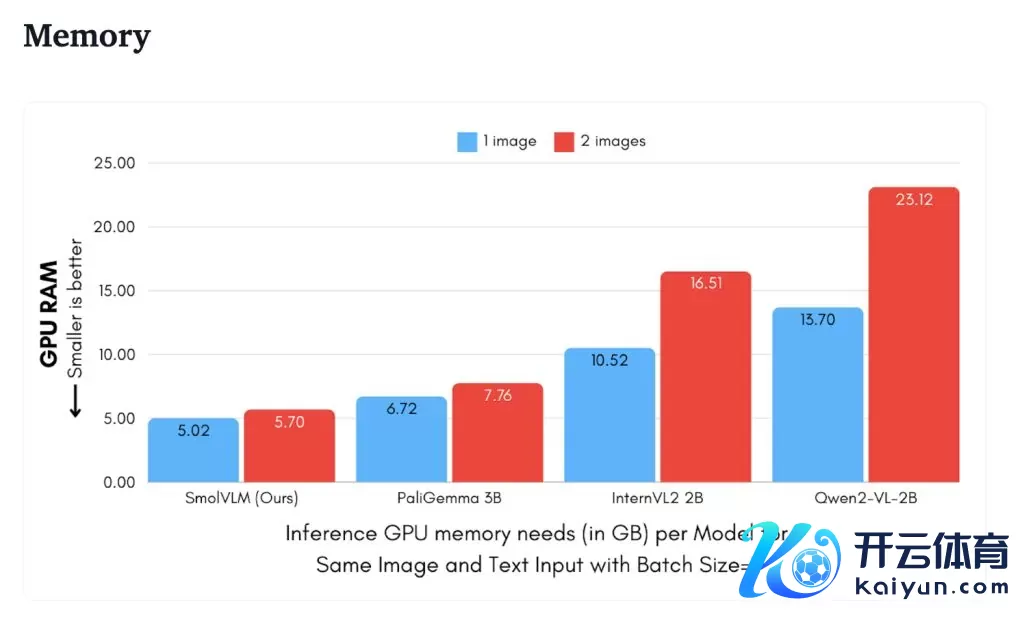
内存
SmolVLM 将 384x384 像素的图像块编码为 81 个 tokens,因此在调换测试图片下,SmolVLM 仅使用 1200 个 tokens,而 Qwen2-VL 则使用 1.6 万个 tokens。
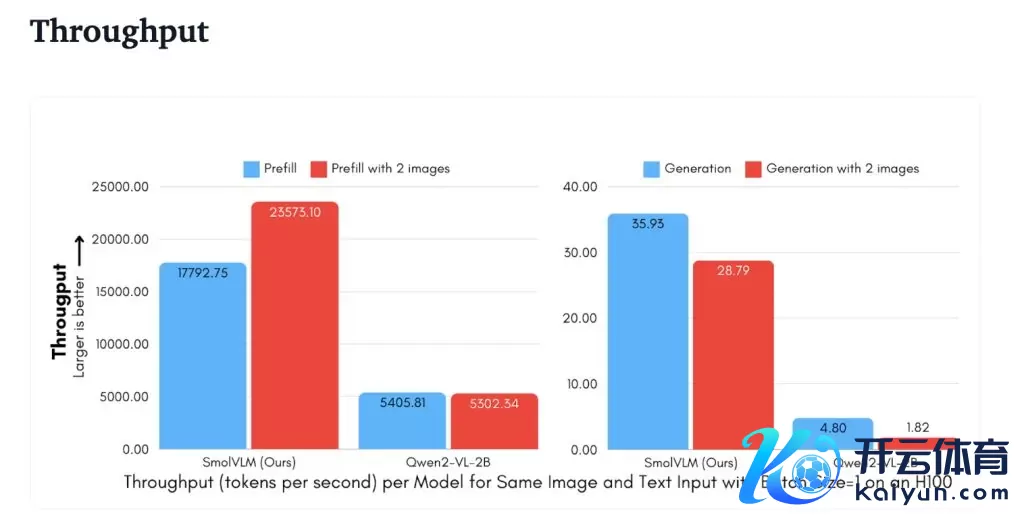
微辞量
SmolVLM 在 MMMU、MathVista、MMStar、DocVQA 和 TextVQA 等多个基准测试中推崇出色,且处理速率比较较 Qwen2-VL,预填充(prefill)微辞量快 3.3 到 4.5 倍,生成微辞量快 7.5 到 16 倍。
 开yun体育网
开yun体育网